
ChainBench benchmarks how AI models generate secure multichain smart contracts, revealing strengths, weaknesses, and real-world risks in agent-assisted blockchain development.
Learn how Circle built ChainBench, an LLM benchmark for multichain smart contract generation, what it reveals about model-agent performance across languages and difficulty levels, how harness choice impacts outcomes, and where frontier models still fail in security-critical edge cases.

From zero-knowledge machine learning (zkML) to agentic economic activity, much of the onchain ecosystem has recently increased its focus on enabling AI systems. Circle has been asking the reverse: how might AI help shape blockchain systems?
AI tools have already supercharged software development in traditional settings. Blockchains, however, present a new challenge: decentralized coordination of an ever-changing system. Smart contracts need to be rigorously tested to ensure reliability and safety.
The challenge of generating high-quality smart contacts is well-known. In February, OpenAI launched EVMBench: an LLM + agent benchmark that measures “the ability of AI agents to detect, patch, and exploit high-severity smart contract vulnerabilities.” Evaluating vulnerabilities from Code4rena auditing competitions, the authors found that frontier models successfully exploited a bootstrap-estimated 72.2% of tasks. They clarify that these results are obtained on tasks that don’t capture the full complexity of real-world smart contracts.
Now we’ve extended that analysis beyond vulnerabilities to include the generation of real-world, enterprise-grade smart contracts. More specifically, we examined single-shot blockchain development capabilities. Today we’re introducing ChainBench: an LLM benchmark that measures how model-agent systems generate functional and secure smart contracts, developed in collaboration with OpenZeppelin.
ChainBench
ChainBench evaluates how useful AI tools are for blockchain developers. Given robust context, the models we tested generated a target contract in accordance with a specification. To best simulate real-world development, we measured model + agent combinations across a suite of 42 tasks covering smart contract operations of varying difficulty. We drew these tasks from modified forms of OpenZeppelin Contracts, the industry-standard smart contract library powering over $35 trillion in value transferred, as well as Circle’s public tests for various products. The tasks ranged in difficulty from simple burn functions to complex treasury operations. A full breakdown of our dataset can be found in our research paper.
Among these tasks, 31 were translation tasks and 11 were generation tasks. This breakdown was chosen to cover common workflows in smart contract development: designing smart contracts (i.e., generation) and making them crosschain compatible (i.e., translation). Each task has four components:
- Instruction Prompt: A markdown file describing the contract or function to implement.
- Contract Environment: A project with all required dependencies.
- Containerized Environment: A docker image to create the requisite environment.
- Verification Suite: A suite of unit tests used to score the model.

A summary of ChainBench task construction and workflow
The translation tasks also included a reference contract — a fully-functional implementation of the smart contract in another language — to aid in the development of the target contract. The generation tasks were not provided this information. As expected, the additional context provided to the translation tasks caused model + agent harnesses to score better.
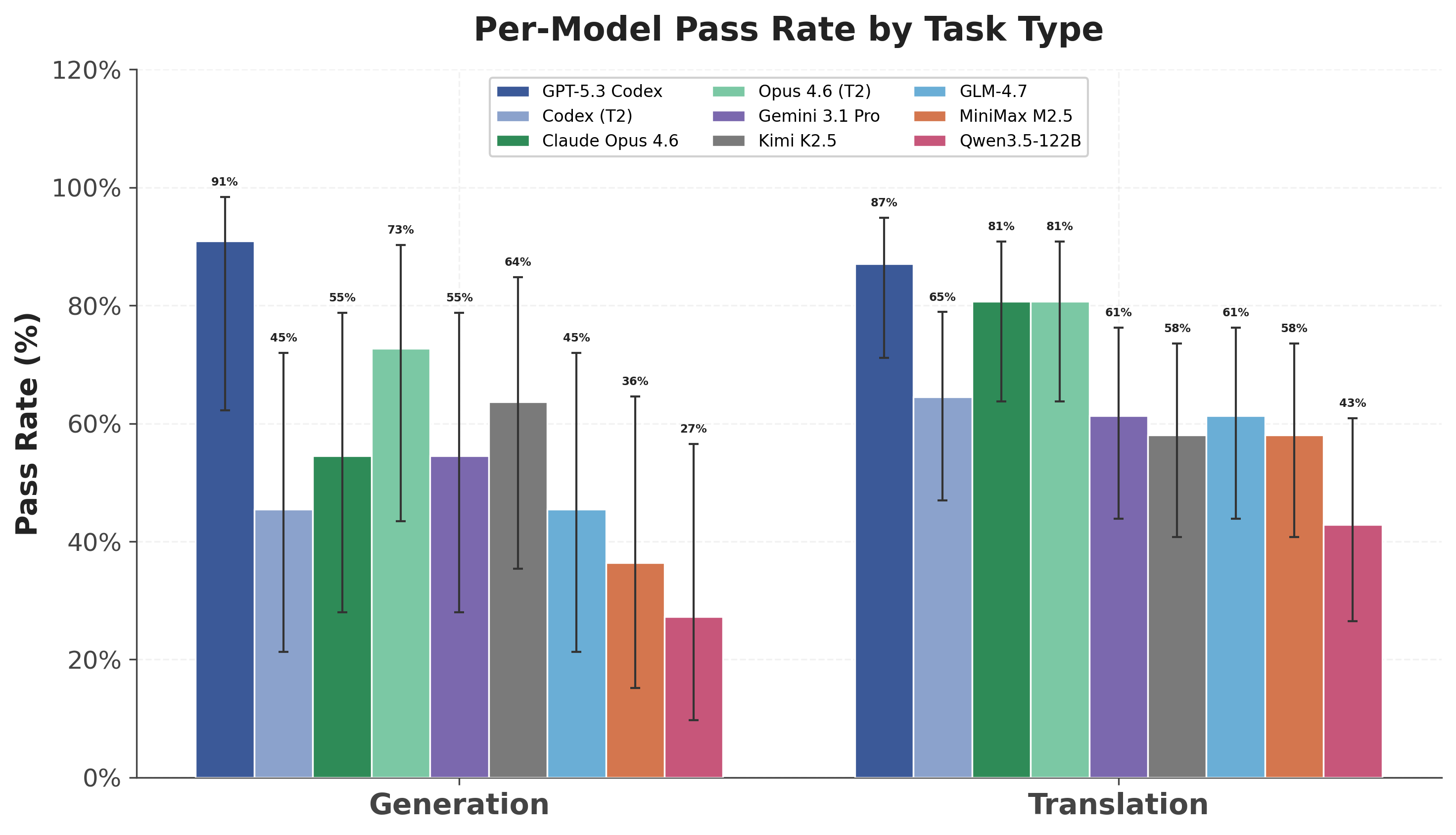
Model + agent harness performance with 95% confidence intervals on success rate
We used binary Pass@1 scoring to best represent success in response to a developer’s request. The model earned a one only if all tests passed. If a run failed to generate code or failed a test, it received a zero. Our aggregate scores represent a simple average over tasks.
Difficulty and Language Affects Performance
Prior to running our testing suite, we assigned each of the 42 tasks a difficulty score. These tasks were largely functional in nature and not necessarily ones with logical mechanism design decisions like those found in DeFi protocols. The difficulty ratings were based on the smart contract behavior required, not just the amount of code the model had to write.
“Easy” tasks tended to involve isolated contract features, including blocklists, simple fee configuration, pausability, and deniability. These usually require a small amount of local state and one clear authorization rule.
“Medium” tasks introduced more stateful behavior. For example, ownership transfer and mint allowances require the model to preserve invariants across multiple actors and state transitions. These are still bounded modules, but mistakes in ordering or authorization can change the security properties of the contract.
“Hard” tasks combined several of these concerns at once. Implementing these tasks require models to coordinate multiple modules. An example of a hard task is implementing a full smart contract either from a specification or by translating it from a different blockchain. For hard tasks, success depends less on writing a recognizable contract pattern and more on preserving the full security model across many interacting pieces.
As expected, models performed well on tasks that were assigned “Easy” or “Medium” ratings, but poorly on those rated “Hard.” A full breakdown by model + agent harness is provided below.
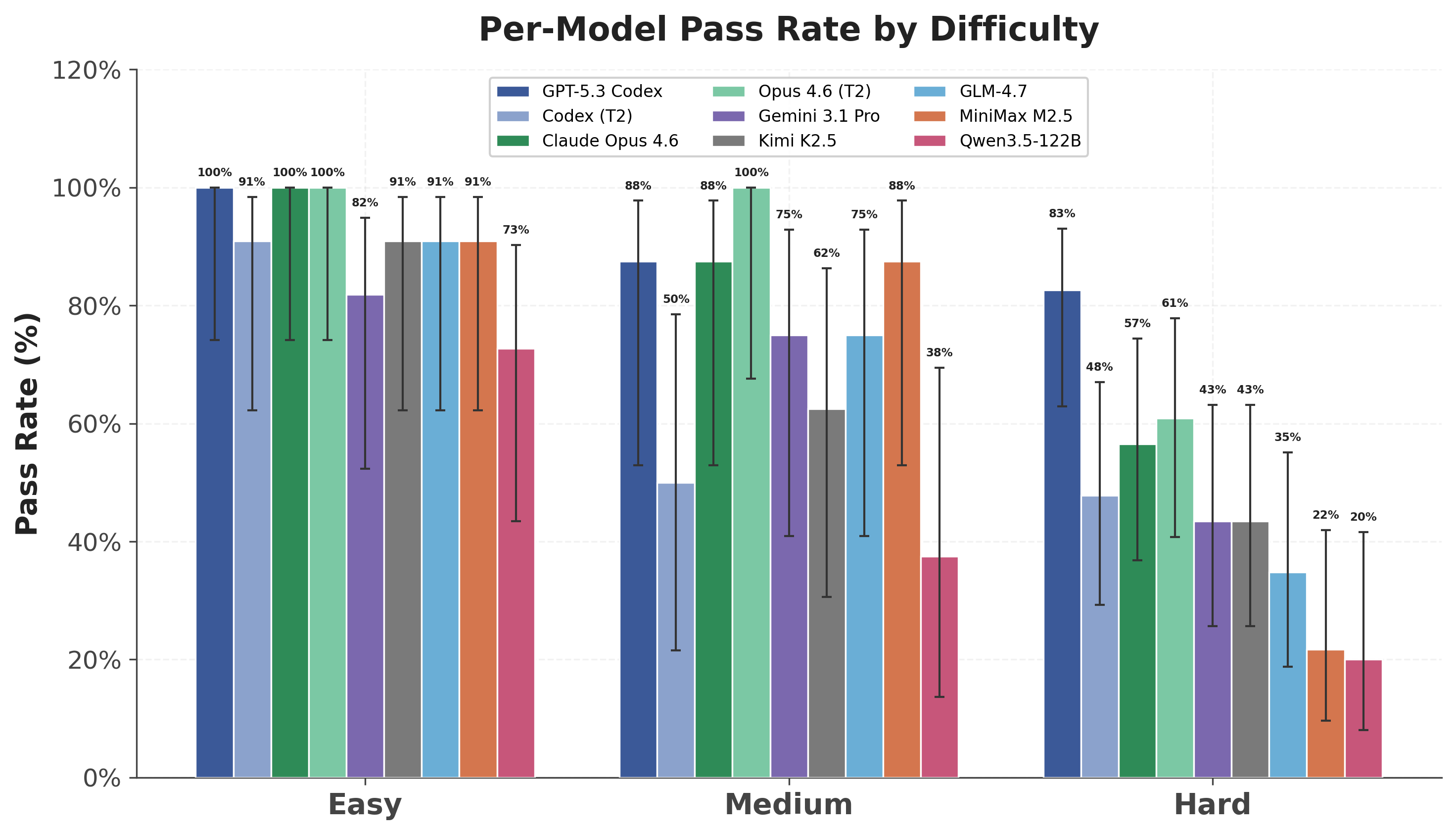
Model + agent harness performance with 95% confidence intervals on success rate
Interestingly, performance on the translation tasks also depended on the language of the target smart contract. We repeated some tasks across different language pairs and found that models could succeed with some languages, yet fail others. NEAR Rust tasks were the best performing, which may be a function of Rust being a common programming language, and therefore more likely represented in LLM pre-training data. Aptos Move and Sui Move, however, are less common in traditional software development, which could explain their lower scores.

Model + agent harness performance with 95% confidence intervals on target contract language
The Model, the Harness, or the Combination?
It's often recommended to run a model on the default harness provided by the lab that trains the model. It is also important to understand the impact a harness could have on a model’s task performance. The interaction between different models and harnesses could surface issues like overtraining a model on a given harness or heightened sensitivity to certain prompts or behaviors that a given harness imposes. To study this impact, we ran Claude Opus 4.6 on Claude Code and GPT-5.3-Codex on the Codex CLI as well as Terminus-2 on all models to understand the impact of harness on ChainBench.
For Claude Opus 4.6, the impact of the harness was minimal. The score moved only slightly when we changed from Claude Code to Terminus-2. Some tasks were successful in one model + agent combination, but not the other. This happened in both directions with neither combination being distinctly better. Terminus-2 fixed some near-misses, while Claude Code performed better on some CCTP Sui tasks. Therefore, we do not think the harness result supports a significant difference for Claude Opus 4.6 beyond select individual tasks.
For GPT-5.3-Codex, however, performance was much better in the Codex CLI harness than in Terminus-2. Looking at the trajectories, the drop did not look like simple randomness. In several Terminus-2 runs with GPT-5.3-Codex, the model stopped after a shallow check, or after passing only the visible tests. In others, especially the larger Sui and NEAR tasks, it entered long compile-and-fix loops without converging. The runs that paired the GPT-5.3-Codex model with the Codex CLI performed better on average, displaying desirable behavior (e.g., inspect the repository, make a focused edit, build or test, and only then finish).
We also tested the impact of system prompts on the harnesses. More specifically, we added Codex-style instructions to the Terminus-2 prompt (e.g., “keep going until the task is solved, run tests when possible, and do not mark the task complete too early.”) This helped on some tasks, but it did not close the gap overall. That makes us hesitant to attribute the difference to one sentence in the prompt or to the base model alone.
ChainBench measures a model-agent system. This is because the same model can behave very differently depending on the harness around it. Here, GPT-5.3-Codex was much better matched to the Codex CLI harness than to the generic Terminus-2 shell loop.
Tasks Beyond the Frontier
Additionally, it is helpful to look at model failures to understand gaps in model capabilities. Doing so can help engineers calibrate their reliance on the models, and help indicate when it’s necessary to edit code and add more testing. We have already crossed a major threshold: frontier models almost always make directionally correct progress on most SWE tasks. But that does not mean they should be trusted to engineer smart contracts zero-shot.
On the contrary, frontier models commonly produced code that generally worked, but missed security-relevant details (e.g., an initialization guard, an error condition, blocklist rule violation, or other unpaused transaction). While blockchain coding capabilities are within reach for many frontier models, their demonstrated work is certainly not as secure and air-tight as high-value, onchain use cases demand.
Creating functional smart contracts is easy; creating secure smart contracts without vulnerabilities is much more difficult
Open-weight models were less successful. A larger share of open-weight model failures never reached semantic testing at all, especially on Sui Move, Aptos Move, and Cairo tasks. The generated code would fail to build because of type errors, missing modules, wrong function signatures, or a misunderstanding of the target chain’s object and module model. Once those models did produce buildable code, many failures were still close. This suggests that the gap is not simply that some models understand smart contracts and others do not. The first gap is reliably producing buildable, integrated code; the second is closing the last-mile invariants that make the contract safe.
Future Work and Collaboration
Our research shows that frontier models can make cutting-edge smart contracts. When tasks are simple, they generate working and safe code in minutes; but as complexity rises, frontier models create code that almost works. It often passes core tests, yet fails edge cases and security checks.
That’s exciting, but it demands extreme caution.
Blockchain exploits do not happen in the happy case. They emerge at the edges: in race conditions and behavior assumed unlikely or impossible. When LLMs generate smart contracts that function and ostensibly look right, it lulls developers into a false sense of security. But when those smart contracts fail under pressure, the results can be disastrous. Because blockchain plumbing is mostly public, smart contract vulnerabilities can be particularly problematic: billions of dollars of value are often secured by protocols whose foundation in code can be inspected (and possibly exploited) by virtually anyone. In these high-stakes scenarios, “almost works” doesn’t cut it.
The internet financial system can’t just be an open-source project, it needs to be secure enough to handle real-world economic use cases. That’s why Circle is launching ChainBench: to empower developers by showing them where AI models create safe smart contracts, and where they often fail.
As blockchains evolve and attackers evolve with them, we will keep updating ChainBench. It’s our goal to see AI capabilities scale alongside onchain use cases, while developers prioritize safety and security along the way. In doing so, we move closer to the frontier of robust smart contract development that’s accessible to all who seek it.
ChainBench is a research benchmark intended to evaluate model-assisted smart contract development workflows and does not certify the security, correctness, or production readiness of AI-generated code. Smart contracts generated or assisted by AI tools may contain vulnerabilities, logic errors, or security-critical failures and should undergo rigorous human review, testing, and auditing prior to deployment.




