

July 14, 2026

As large language model (LLM)-based agents increasingly navigate the web on behalf of users, their browsing behavior is reshaping the internet’s economic foundations. These systems can browse hundreds of pages per second, and yet none of them result in monetizable ad impressions of clicks. Ad revenue has historically given publishers and writers an incentive to provide open access to their content. In the age of agentic search, this incentive model is breaking down.
To understand the extent of this we conducted a study comparing agentic search behavior to human search. Three clear patterns emerged:
Ironically, these powerful agents are trained on the data from the open web. Content creators and publishers who built that knowledge ecosystem receive no compensation for the value extracted, neither during pretraining and real-time operation.
In this post, we quantify this impact and explore its implications. By measuring the actual traffic patterns and value extraction, we can begin to identify paths toward sustainable monetization before the open web fragments into walled gardens or collapses entirely.
As LLM API providers and application developers have realized the power of coupling LLMs with research capabilities, a growing ecosystem of agentic search tools has emerged.
At one end of the spectrum are systems where an LLM uses a basic `web_search` tool, calling a traditional web search API like `serpAPI` or Google Search to retrieve results, then summarize or rerank them.
At the other end are powerful systems like Yutori Scouts, where a single query can run for days, spawn sub-agents, and generate human-readable reports.(For example: Over seven days, Yutori generated 104 reports,each produced by 11 web-searching agents.)

Similarly, Parallel.ai can crawl thousands of websites for a single query, producing highly detailed responses.

As the METR benchmark [3] shows, language models are becoming trained to complete increasingly long-horizon tasks, which suggests their capacity for complex, multi-step search will inevitably increase.

We define this as search explosion: the dramatic increase in the number of page visits a single search query produces.
To ground our analysis, we used the Researchy Questions dataset [1], a recent release of ~100k real-world search queries mined from commercial search logs. The dataset focuses on non-factoid, multi-perspective, and decompositional questions, which, unlike factoid queries that can usually be answered with a single sentence or a quick lookup, are the kinds of questions that require synthesis across multiple sources, often with conflicting perspectives.
Each query in the dataset is linked to the set of documents that real users clicked on (via ClueWeb22 dataset [2]), and includes the relative click distribution (Click_Cnt) across those documents. For example, a Click_Cnt of 0.25 indicates that 25% of all clicks for that query went to that document. These values serve as an implicit relevance signal, showing which documents users collectively found useful and typically summing to approximately 1 across all documents per query.
Within this dataset, we divided queries into two categories to study search explosion:
By contrasting these two classes, we established baselines for human search effort: one where a single click sufficed and one where the search process naturally required breadth. Running the same queries through agentic AI systems lets us measure how machine browsing behavior diverges from distinctly human patterns.
To quantify traffic generated by agentic AI systems, we leverage four commercially available APIs that represent the current state of AI-powered search: Exa Research [4] , Parallel.ai Deep Research [5] , OpenAI Deep Research [6], and Perplexity Deep Research [7].
Several of these services offer multiple model tiers that let users to dial up the computational intensity and, consequently, the number of pages visited.
We ran queries from the Researchy Questions dataset through each system to measure the search explosion effect.
The table below shows the search explosion effect for queries where human users typically found their answer with a single click (Click_cnt ≥ 0.9).
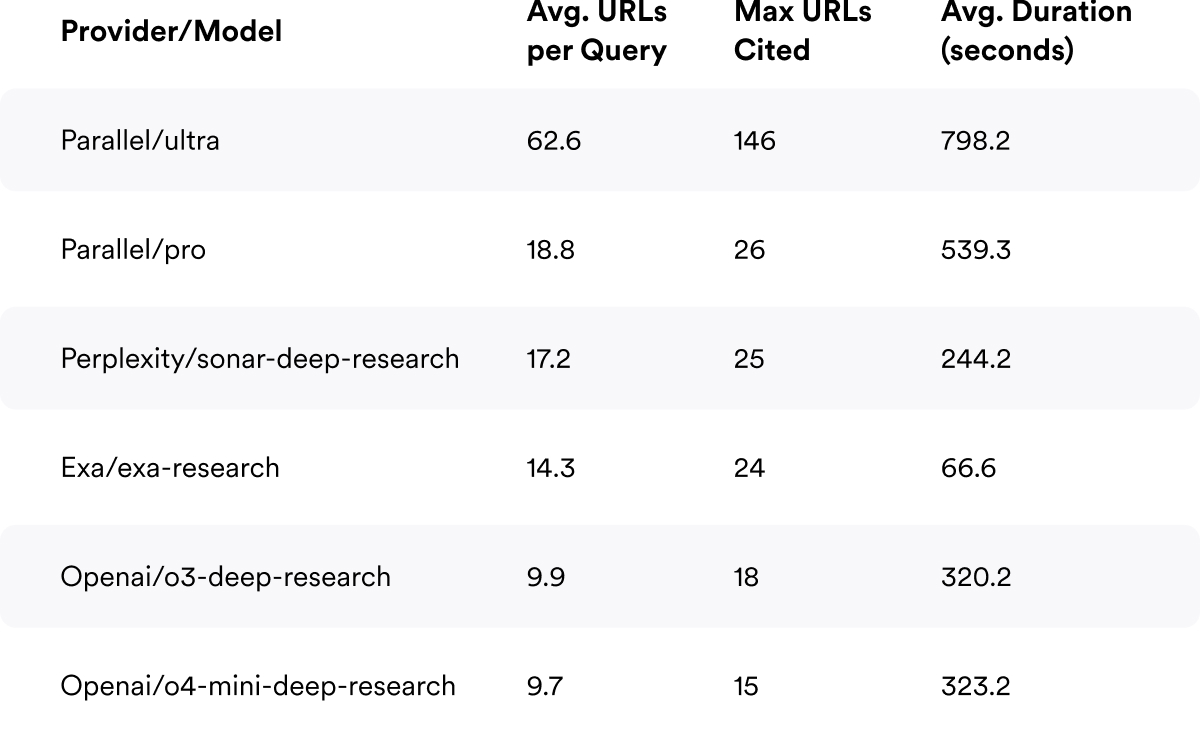
Even for straightforward queries, AI systems visit 10-60+ pages on average, with Parallel's Ultra model reaching up to 146 pages for a single query. This represents a 10-60x multiplication in web traffic compared to human behavior.
The more powerful models — Parallel Ultra and Firecrawl — show the most aggressive crawling behavior, suggesting that as users adopt higher-tier models for better results, traffic amplification intensifies.
For the maximum case (146 pages), a human would need over an hour just to skim the content, not counting time for note-taking or synthesis. This illustrates both the efficiency and scale of agentic systems, and the degree to which they consume web resources without creating revenue in return.
Note: This analysis represents only a subset of available systems. Some tools like Yutori Scouts [8] don't provide APIs, while others (like Parallel.ai, Ultra-4x, and Ultra-8x ) likely generate proportionally more traffic. Additionally, these figures reflect only the cited sources in the final output; the actual pages reviewed but not included in results are likely significantly higher.
The future of the open web depends on micropayments for content and APIs. The autonomously browsing AI agents would pay a small fee for the content or service they want to access and subsidize the human activity. x402 ecosystem enables this paradigm. USDC provides a payment rail which enables agentic microtransactions. In order to minimize the gas fees Circle is building cross-chain micropayments to help make this future a reality.
.jpg)


